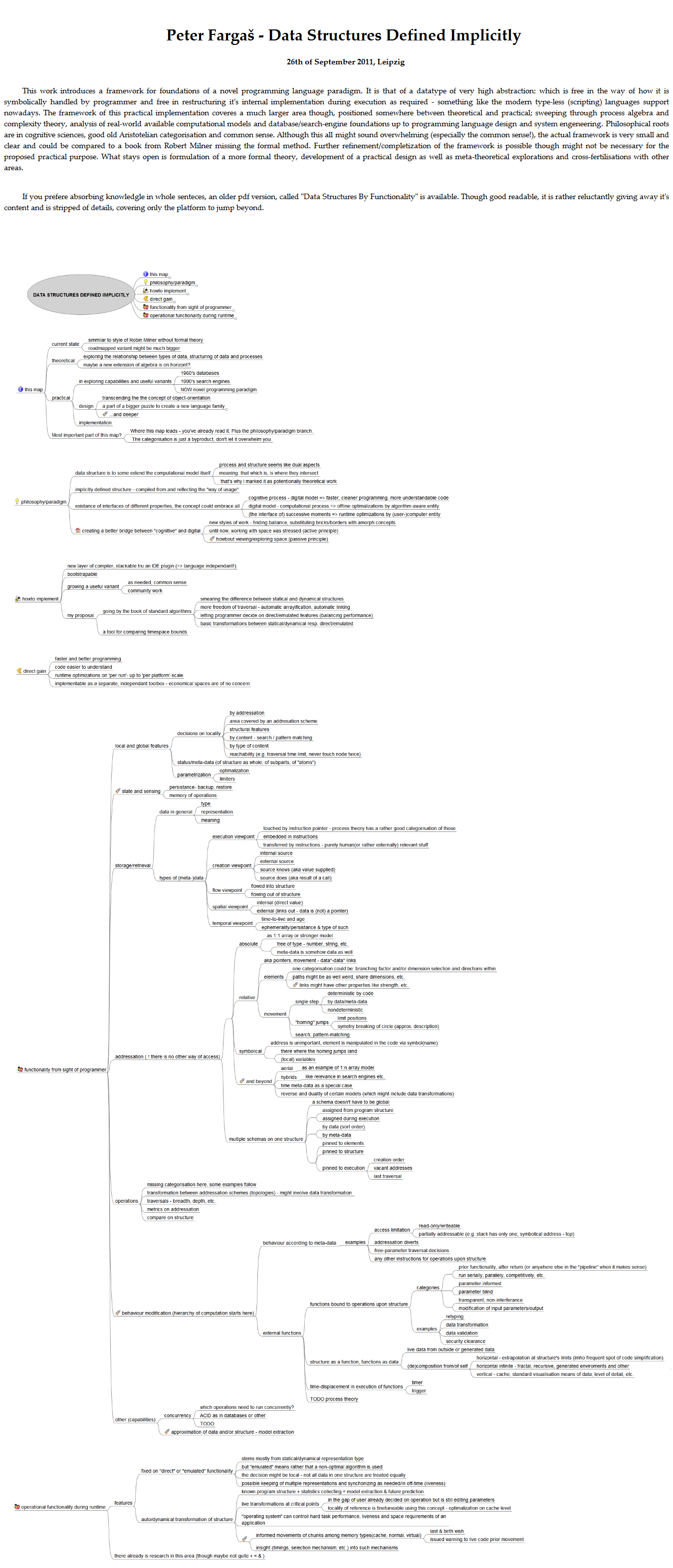
/article/inspirative/dataStructuresByFunctionality.php
Data Structures by Functionality
This document belongs to the topic of "better programming by better programming language design" and addresses the problematic from the viewpoint of data. Due to the overlapping nature, not all aspects-solutions are covered here. I am preparing further texts which roughly will have the titles "Interpreted and rooted data" and as I hope "Visual data traversal".
Introduction
While no paradigm quite captures the essence, there is a well established paradigm of data flow, which looks at a program from the point of manipulation and transfer of data, ultimately reducing everything to pure information, places of it's transformation and the time-line of it's movement.
There are two sides to efficiency of programming: the process of programming itself and the resulting program. If we look at the first one, it consists of various factors such as the time needed to write a program, the complexity of code, optimization possibilities(per hand or by a compiler), and of the debugging. The latter one, efficiency of the resulting program consists of, for the purposes of this document, the factors of the still seldom optimizations at install time or during the run of the program.
All of those depend heavily on data structures used. The computational efficiency of algorithms comes very often from the speed of/readiness access to pieces of data needed during a short time window. The simplicity and readability of the code depends on having a clear structure on basis of which commands, branching, etc. are clear in context and purpose. I want to point out that the optimal structures for those two areas may differ to a great extent.
From the practical side, C++ programmers often look down on Java programs, because the data structures are seldom optimized and are rather build from prefabricated elements which are, among other, overpowered for the task. Database programmers know that the performance of a database begins at the level of structure of tables, depending on the way how program stores, searches and retrieves information.
One of the turning points in creation of an efficient programming language is thus the available toolbox of structuring data.
On nuts and bolts
The very smallest substrate of data is a single element of the hardware's memory storage, which is at our current implementation, in contrast to the standard Turing model, directly addressable. Basic data types arise from those, either through size or interpretation. A potential area of run-time efficiency, which might be very well out of our reach and maybe beyond what could be called sane, would be compiler's capability of minimizing distance of basic data (their addresses during execution) which are (computably known to be) needed within a short period of time resp. ordering such in accord with underlying hardware's memory access (e.g. caching) "algorithms".
This basic data is often, in modern programming languages, encapsulated in functionality, a popular one being called Object which may come in super lightweight or extremely rich variants. While being very practical for the programming, this is however simply a programming language construct and there is no reason why it's existence should reflect all the time in the compiled code. As I see it, on certain occasions, dependent on which constructs are required from the code itself and of the embedding framework (e.g. run-time environment), this could get stripped in the resulting executable. I read somewhere a very witty remark on object oriented programming: "you simply wanted a banana, but what you got is a banana held by a gorilla and all around a jungle". The jungle might be practical for purposes of debugging or cross-platform functionality, the gorilla (unluckily unwanting to hold the banana without a jungle around) for purposes of programming, but such could get stripped at some point, resp. stripped and wrapped on a higher level. This decision should not be that hard to compute so it's probably already implemented in state-of-the-art compilers.
Composite structures in current systems
Prefabricated structures are commonly used, sometimes custom ones get implemented. This either overshoots the functionality needed or is tedious and as requirements get discovered during the implementation process, per hand re-factoring is often needed. Algorithms operating on the structure at various places of the program might have very different requirements and the simplicity of code might suffer as well.
Ideal functionality of data structures
Data structures of various capabilities are commonly in use. A sample categorization with simple examples follows:
-
status information and parametrization
- size, empty, bufferSize -
absolute addressation
- arrays -
relative addressation/navigation
- linked lists, trees, iterators -
element access limitations
- read only, read-write, stack -
statical/dynamical
- in respect to the size/structure - array or arrayList -
element validation, transformation, consistency checking
- strictly typed, only specific values -
concurrent operations
- write one & read many, write on non-conflicting positions, as well as dynamical during traversal -
multi-meaning data
- self-describing structures, commands on e.g. navigation, pointers
status information and parametrization
Knowing the state of the structure is important for purposes of limit conditions. Parametrization is a way of fine-tuning the performance.
absolute addressation
Self-explanatory, each element can be accessed by means of a statical identifier. There may be more than one addressation superimposed on one data structure.
relative addressation/navigation
The data structure implements something equivalent to head in the Turing model. Multiple heads and limit homing can be supported. The type of available movement depends on the structure - one useful categorization could be: direction, branching factor and dimension. As well, belonging to the relative addressation is information on the path taken or available. For multi-graphs, a path from a node to itself is perfectly valid.
element access limitations
Some structures are good enough as fill once-read only, some make sense only with write access. This might be coupled with the previous two concepts, supporting only one or none of the two modes of access. A special category of access is that of fixed position: stack and queue, this can however be attributed to a sub-mode of one of the previous modes of access.
statical/dynamical
A screen buffer is an example of structure where statical structure is enough. Implementing a dynamical structure which seldom changes through means of a statical structure might be more efficient. There might be a requirement of a pinpointed addressation schema, one where absolute addresses stay statical upon the change of structure, while the navigation reflects new structure. Dynamical structures of a common functionality can vary quite a lot, they may be optimized for single element add, bulk-filling, etc.
element validation, transformation, consistency checking
This consists of multiple subcategories. Multi-threaded access has many forms, there might be operations only on data but on the structure as well. Some combination from single/multiple read, single/multiple - non-conflicting/serialized write, non-conflicting dynamical operations might be wished for. The other subcategory is that of a single thread performing operations of different kinds on the structure. This idea arose from an observation that during use of iterators, elements mostly might not be added or removed.
concurrent operations
Before writing data, data often needs to get checked against some model, including security clearance of caller. Upon read, a transformation from one data type to another might take place. More complicated types of reads and writes, ones where (de)composition of data might take place
multi-meaning data
Data at various positions might have different meaning attached to them. A function which determines the type of data by its position or value and functions which then get executed upon certain events on such can simplify the use of the structure. While the previous concept already heads in the direction, this embeds a full computational model inside the data structure itself.
Conclusion
As one can see, most of the concepts are combine-able and can be supported either directly or through emulation of features. What follows is the proposed implementation - depending on the features programmer uses, such data structure gets compiled. Dynamical transformations should be largely possible. The programmer could specifically indicate a wished structure for a purpose of an algorithm. Statistical tools for optimizing emulated/direct features should be at disposal as well as auto-optimize during the run by exchanging emulated feature by a direct one while slowing down other portions of code should be possible.
The concept is not implementable by object-oriented means, in meta-language maybe. However, this all could reach almost the complexity of a modern database system and implementation in full scale, would be that of a compiler - programming language couple embracing this concept.
Fatal error: Uncaught Error: Call to undefined function output() in /data/d/4/d49051aa-7814-43a5-b220-a179f6df99db/informatik-handwerk.de/sub/knowledge-transfer/article/inspirative/dataStructuresByFunctionality.php:599 Stack trace: #0 {main} thrown in /data/d/4/d49051aa-7814-43a5-b220-a179f6df99db/informatik-handwerk.de/sub/knowledge-transfer/article/inspirative/dataStructuresByFunctionality.php on line 599